DiffSLT generates diverse yet accurate translations by leveraging a diffusion model.

Sign language translation (SLT) is challenging, as it involves converting sign language videos into natural language. Previous studies have prioritized accuracy over diversity. However, diversity is crucial for handling lexical and syntactic ambiguities in machine translation, suggesting it could similarly benefit SLT.
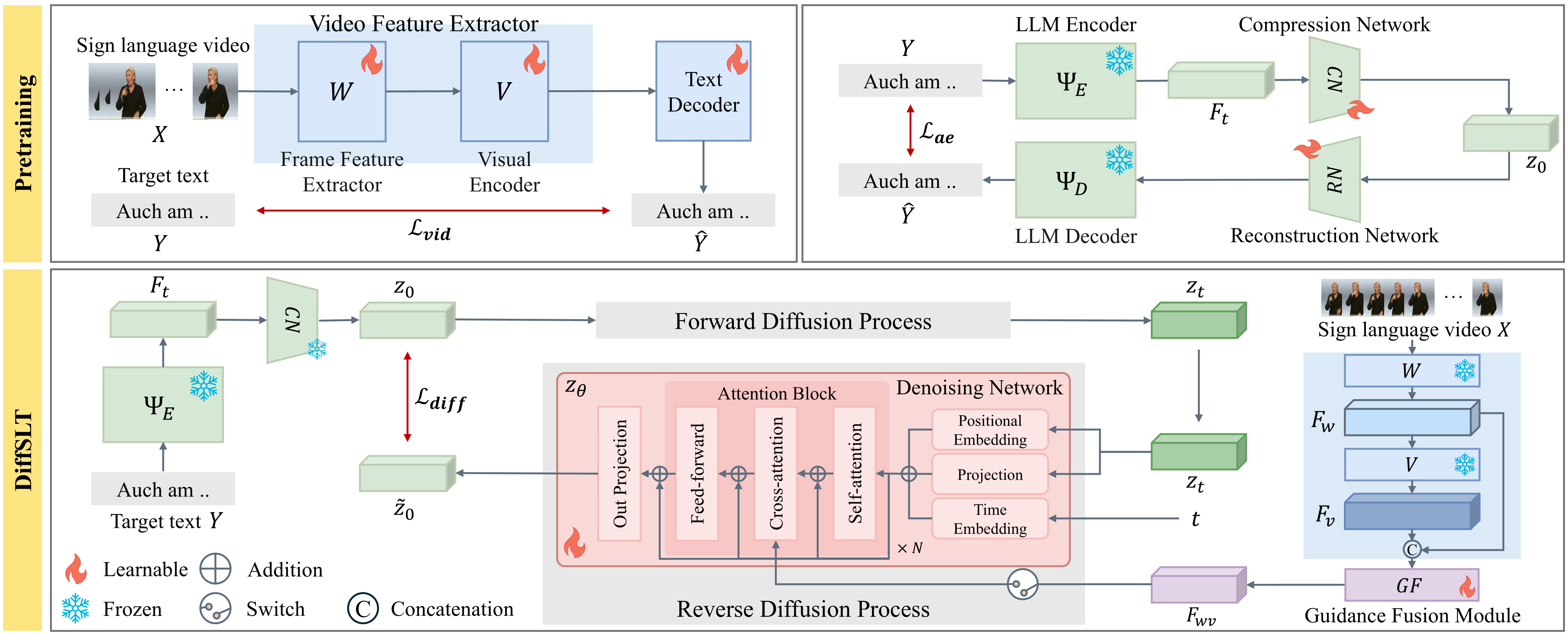
In this work, we propose DiffSLT, a novel gloss-free SLT framework that leverages a diffusion model, enabling diverse translations while preserving sign language semantics. DiffSLT transforms random noise into the target latent representation, conditioned on the visual features of input video. To enhance visual conditioning, we design Guidance Fusion Module, which fully utilizes the multi-level spatiotemporal information of the visual features. We also introduce DiffSLT-P, a DiffSLT variant that conditions on pseudo-glosses and visual features, providing key textual guidance and reducing the modality gap.
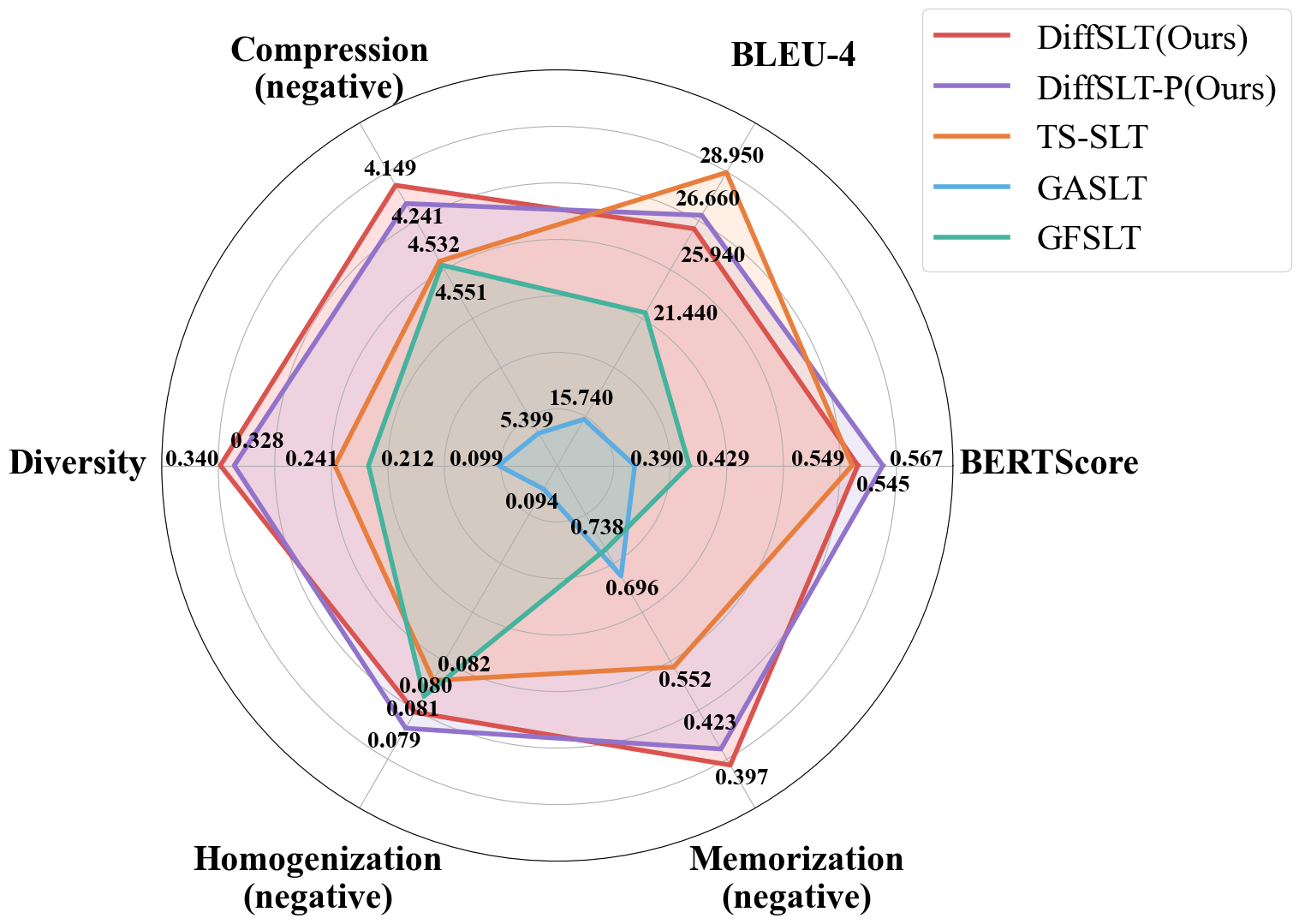
As a result, DiffSLT and DiffSLT-P significantly improve diversity over previous gloss-free SLT methods and achieve state-of-the-art performance on two SLT datasets, thereby markedly improving translation quality.


@article{moon2024diffslt,
title={DiffSLT: Enhancing Diversity in Sign Language Translation via Diffusion Model},
author={JiHwan Moon and Jihoon Park and Jungeun Kim and Jongseong Bae and Hyeongwoo Jeon and Ha Young Kim},
year={2024},
}